protobuf是怎么序列化的
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。
背景
目前主流的几种数据交互的格式主要有xml、json、protobuf等等。xml和json我相信大家都很了解了。
xml在webservice中应用最为广泛,但是相比于json,它的数据更加冗余,因为需要成对的闭合标签。json使用了键值对的方式,不仅压缩了一定的数据空间,同时也具有可读性。json一般的web项目中,最流行的主要还是json。因为浏览器对于json数据支持非常好,有很多内建的函数支持。- 而
protobuf是后起之秀,是谷歌开源的一种数据格式,适合高性能,对响应速度有要求的数据传输场景。因为profobuf是二进制数据格式,需要编码和解码。数据本身不具有可读性。因此只能反序列化之后得到真正可读的数据。
protobuf 是一种google发明的数据序列化机制。官网的解释是:
protocol buffers(简称protobuf)是google的语言中立、平台中立、可扩展的机制,用来对结构化数据进行序列化,类似于xml,但是更小、更快、更简单。只要定义好如何结构化你的数据,就可以使用生成好的代码取写和读取各种数据流的数据,支持各种语言。
现在越来越多的互联网公司选择使用protobuf来进行序列化,就是因为它的优势。它被广泛应用于RPC调用,数据存储。
protobuf的核心就是它的.proto文件,定义了数据的格式,类型和顺序。
syntax = "proto3";
message Student {
optional int32 id = 1;
optional string name = 2;
}
注意: protobuf语法有proto2和proto3,现在一般用proto3。支持更多语言且更简洁。
定义好proto文件后,通过protobuf提供的protoc编译器对其进行编译。它支持主流的编程语言:C++, C#, Dart, Go, Java, Kotlin, Python等。
我们只需要定义好一份.proto文件,序列化和反序列化可以使用不同的语言。
如果说protobuf有什么缺点的话,那就是序列化之后的数据是二进制的,可读性差这一点了。
假设你对protobuf有基础的了解并使用过它,想深入了解一下protobuf的原理:
- protobuf的数据是怎么序列化的?
- protobuf是怎么保持向后兼容性的?
- protobuf的原理是什么?
- protobuf是怎么极致的利用空间来储存数据的?
那这篇文章适合你。
为什么要讲序列化的原理和过程呢?
写这篇文章的原因是有一个同事问我可不可以在某个protobuf结构的中间加一个字段,然后把后面所有的字段标识(标签的数字,比如上面的message的id的字段标识是1)都加1。
因为他觉得protobuf跟json类似,是用字段名来标识数据的Key的,所以顺序和字段标识不重要。
重点: 这是错的。字段标识很重要,为了保持兼容性,定义好之后是不能修改的。增加新的字段只能增加新的字段标识。
储备知识
要了解Protobuf的编码和序列化,我们首先需要了解点技术的储备知识点。弄懂了储备知识点之后,才能更快的让我们理解protobuf的序列化过程。
储备知识包括:
- Varint编码
- Zigzag编码
如果你已经了解了这两个技术点,或者不想了解这些编码细节,可以直接跳到下个章节:Protobuf序列化。
Varint编码
Varint编码是一种变长的编码方式,编码原理是用字节表示数字,值越小的数字,使用越少的字节数表示。因此,可以通过减少表示数字的字节数进行数据压缩。
对int32类型的数字,一般需要4个字节表示。如果采用Varint编码,对于很小的int32类型数字,则可以用1个字节来表示;虽然大的数字会需要5个字节来表示,但大多数情况下,消息都不会有很大的数字,所以采用Varint编码方式总是可以用更少的字节数来表示数字。
Varint编码后每个字节的最高位都有特殊含义:
- 如果是1,表示后续的字节也是数字的一部分。
- 如果是0,表示本字节是最后一个字节,且剩余7位都用来表示数字。
重点: 每个字节的最高一位只是标识位,没有具体数字含义。
我们举两个例子可能说的更清楚一点:
例一:数字1
这里是数字1,它是一个单字节,只需要一个字节就可以表示。
[0]000 0001
例二:数字300
这里是数字300,这有点复杂。单字节最大只能储存2^7-1, 也就是 0111 1111, 肯定是不够的。[注:最高位是特殊含义的标识符]
300 = 256 + 32 + 8 + 4 = 0000 0001 0010 1100
到这一步我相信都能看懂。
我们继续一步推到底。
300
= 256 + 32 + 8 + 4
= 0000 0001 0010 1100 (二进制)
= 0000010 0101100 (每7位代表一个字节)
= 0101100 0000010 (小端储存,低位在前)
= 10101100 00000010 (高位补1/0)
所以300需要两个字节储存。
更大的数据都是类似的方式转换,对于很大的整数,32/7=4.57,向上取整是5,所以我们最大需要5字节来表示一个大的32位整数。
所以我们使用Varint编码,需要1~5个字节表示。因为大部分使用的数字都比较小,所以平均下来比较省空间。这也是为什么protobuf使用Varint的原因。
Zigzag编码
由于负数的补码表示很大(最高位是符号位为1),直接使用Varint编码,会占用较多的字节。
这种情况使用了ZigZag编码,转换成比较小的正数,再使用Varint编码,这样最终生成的数据占用较少的字节。
Zigazg编码是一种变长的编码方式,其编码原理是使用无符号数来表示有符号数字,使得绝对值小的数字都可以采用较少字节来表示,特别对表示负数的数据能更好地进行数据压缩。
Zigzag编码对Varint编码在表示负数时不足的补充,从而更好的帮助Protobuf进行数据的压缩。因此,如果提前预知字段值是可能取负数的时候,需要采用sint32/sint64数据类型。
Protobuf通过Varint和Zigzag编码后,大大减少了字段值占用字节数。
简单来说: 对于小的负数,比如-2,如果使用Varint编码,在计算机内,负数一般会被表示为很大的整数,因为计算机定义负数的符号位为数字的最高位。所以这个-2会占用5个字节。因为负数的最高位是1,会被当做很大的整数去处理。
而我们使用Zigzag+varint编码的方式,(使用protobuf定义的sint32/sint64类型)就会将有符号数转换成无符号数,再采用Varint编码,数字较小的负数,最终占用的字节数也就更少。
sint32类型的数字n:
(n << 1) ^ (n >> 31)
sint64类型的数字n:
(n << 1) ^ (n >> 63)
| 原始数字 | 编码后 |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
通过位运算算法和编码后的值的规律,我们可以看到,其实就是把最高位的符号位放到最低位,其他位左移一位。让绝对值相等的正负数,Zigzag编码后的数字相邻。
绝对值小的值Zigzag编码后的值也更小。然后使用Varint编码后占用的字节数也更少。
Protobuf序列化
花了半天时间了解了两种编码,终于要讲文章的主题,Protobuf序列化了。
要了解Protobuf序列化,我们还是需要了解两个知识点:
- Wire Type类型
- T-L-V储存方式。(Tag - Length — Value)
这两个要一起讲。
Wire Type
Wire Type是google为protobuf专门定义的类型,不同的Wire Type最终序列化为二进制数据流的格式不一样。这样我们在序列化和反序列化的时候,很容易通过这个Wire Type来解析后续数据。
Wire Type是用来生成Tag用的,准确的来说,Tag包含了字段标识和Wire Type。这个Tag在后续讲T-L-V储存的时候会讲到。
这是WireType的定义。
enum WireType {
WIRETYPE_VARINT = 0,
WIRETYPE_FIXED64 = 1,
WIRETYPE_LENGTH_DELIMITED = 2,
WIRETYPE_START_GROUP = 3, //deprecated
WIRETYPE_END_GROUP = 4, //deprecated
WIRETYPE_FIXED32 = 5
};
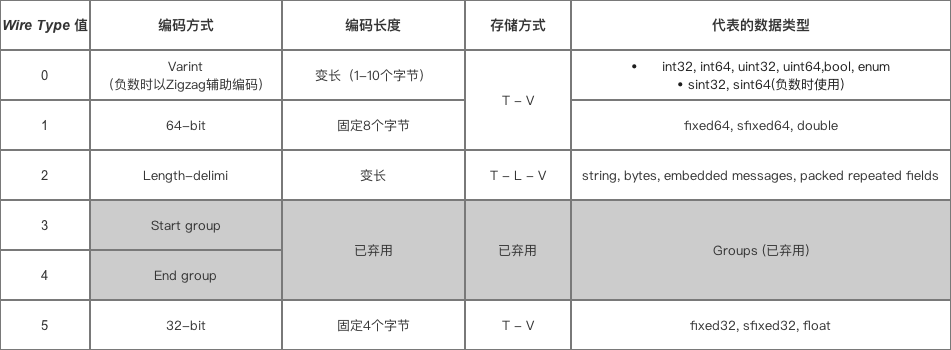
这是各个Wire Type对应的具体类型。
每个Wire Type可以对应多个具体的数据类型,因为我们有.proto文件,序列化和反序列化都是基于proto文件的,所以我们是明确知道类型的。
问题: 那为什么需要把Wire Type编码到数据里面呢,因为不同的Wire Type对应的储存方式不同,可以通过序列化的Wire Type知道后续的数据是怎么储存的。
看上图可知,当我们从Tag里面读到:
- Wire Type=0时,T-V 储存,V是Varint编码方式,编码长度是1-10字节。
- Wire Type=1时,T-V 储存,V是固定的64位,编码长度是8个字节。
- Wire Type=5时,T-V 储存,V是固定的32位,编码长度是4个字节。
- Wire Type=3/4已经废弃不用。
- Wire Type=2时,也是最复杂的一种,T-L-V储存。需要一个Length来记录Value的长度。Value是编码后的值。
通过不同的Wire Type使用不同的储存方式,来最大化的节省空间。
T-L-V储存方式
T-L-V(Tag - Length - Value),即标签-长度-字段值的存储方式,其原理是以标签-长度-字段值表示单个数据,最终将所有数据拼接成一个字节流,从而实现数据存储的功能。
其中Length可选存储,如储存Varint编码数据就不需要存储Length,此时为T-V存储方式。
T-L-V 存储方式的优点:
- 不需要分隔符就能分隔开字段,减少了分隔符的使用。
- 各字段存储得非常紧凑,存储空间利用率非常高。
- 如果某个字段没有被设置字段值,那么该字段在序列化时的数据中是
完全不存在的,即不需要编码,相应字段在解码时会被设置为默认值。
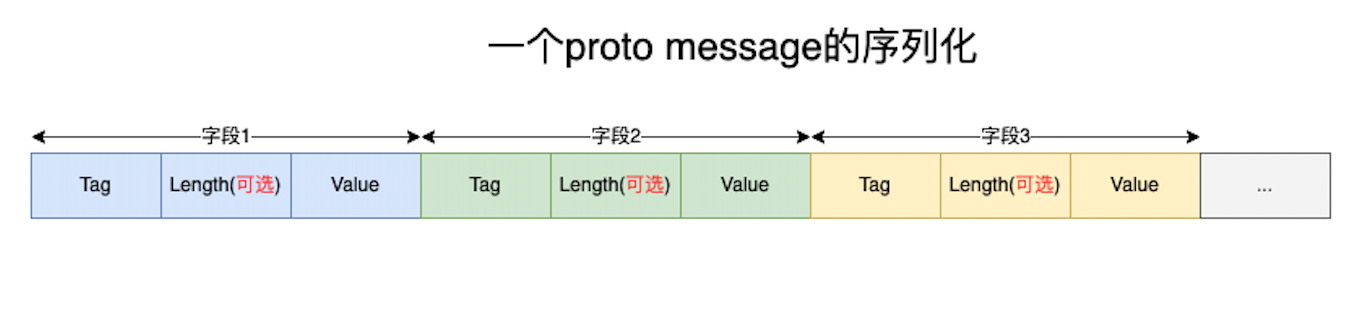
Tag 标签
Tag 就是字段标识号+Wire Type的Varint编码格式。最少1字节。
因为Wire Type只有这6个定义,所以使用3bit完全够用。 Tag的最低三位表示Wire Type,高位表示字段标识号, Tag标签所占用的长度,取决于字段标识号的大小。
Wire Type只有六种类型,所以用三位二进制数完全足够表示。
Tag = (字段标识号 << 3) | WireType
也就是如果如果字段标识号 <= 15 (4bit),那么Tag就只需要一字节。
Length 长度
Length 通过上图可知,它是可选的。只有Wire Type = 2时,才需要Length。
Value:只有WireType=2时,具体长度由Length指定。其他的Wire Type, 不需要Length也知道Value的长度。可以参考上面的Wire Type图对应的编码长度。
不同Wire Type的数据序列化方式
下面我们就针对不同的Wir eType,来以一个个分析,我们的数据是怎么编码的。
WireType = 0/1/5时
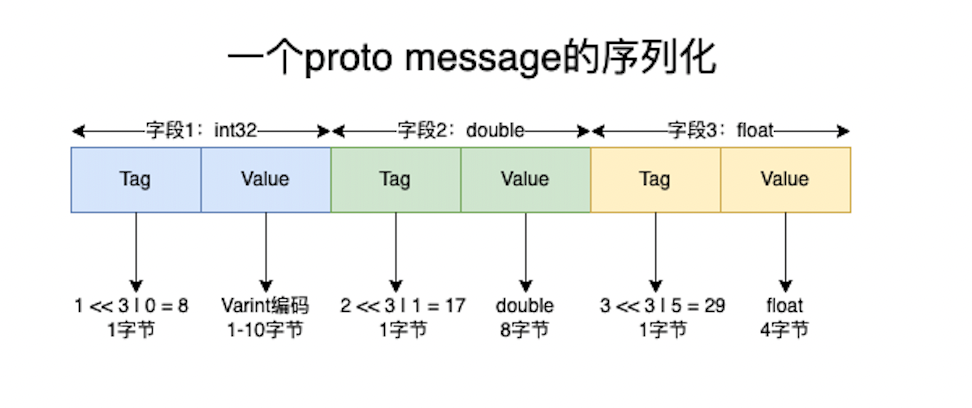
所有的Tag都是Varint,Tag = (字段标识号 << 3) | WireType。
- int32: Wire Type = 0, Value:Varint,变长,1-10字节。(最大64位Varint)。
- double: Wire Type = 1, Value: double,固定8字节。
- float: Wire Type = 5, Value: float,固定4字节。
可以看到这几种类型,不需要指定Length,通过Wire Type和Varint极高的利用了字节空间。
WireType = 2时
相比较其他Wire Type多了一个Length,用于标识Value的长度。Length使用Varint编码。
Value:消息字段经过编码后的值。
其中Value也需要区分几种类型:
- String类型。
- 嵌套消息类型(Message)
- 通过packed修饰的 repeat 字段(即packed repeated fields)
String类型 其中String类型使用UTF8编码。
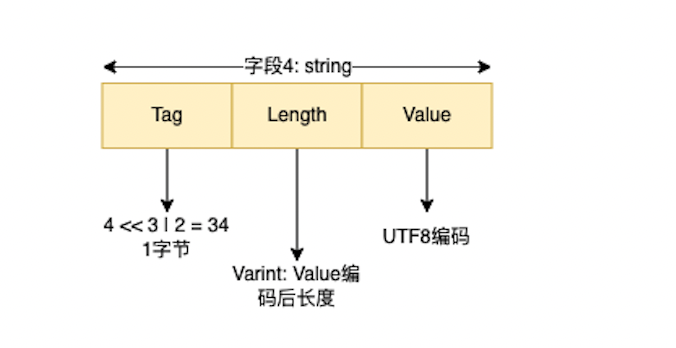
message Test
{
...
optional string str = 4;
...
}
// 将str设置为:testing
Test.setStr(“testing”)
// 经过protobuf编码序列化后的数据以二进制的方式输出
// 输出为:18, 7, 116, 101, 115, 116, 105, 110, 103
输出为二进制数据流,展示为数字,方便可读。
Tag = 4 << 3 | 2 = 34
Length = 7
Value = UTF8("testing") = 116, 101, 115, 116, 105, 110, 103
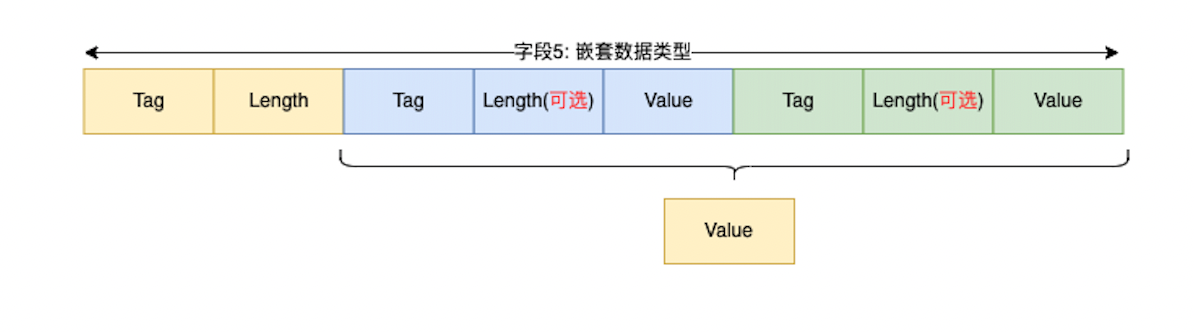
嵌套消息类型
message Test
{
...
optional Internal internal = 5;
...
}
message Internal
{
optional string a = 1;
optional string b = 2;
}
嵌套消息类型,就是message里面套一个message,其实就是把内层的消息的T-L-V数据储存作为外层数据的Value。
外部的Length代表整个Value的长度,也就是内部的message的长度。
内部的Message就是另一个T-L-V模型。
通过packed修饰的 repeat 字段
proto2: 由于历史原因,标量数字类型(例如 int32、int64、enum)的重复字段没有尽可能高效地编码。新代码应使用特殊选项 [packed = true] 以获得更有效的编码。proto3: 此字段可以在格式良好的消息中重复任意次数(包括零次)。重复值的顺序将被保留。在 proto3 中,标量数字类型(例如 int32、int64、enum)的重复字段默认使用packed编码。
message Test
{
...
repeated int32 lists = 6; // 表达方式1:不带packed=true
repeated int32 lists = 7 [packed=true]; // 表达方式2:带packed=true
}
也就是说packed=true是专门针对标量数字类型做的一个编码空间优化策略。对于proto3而言,它是默认使用的,对于proto2而言,由于历史原因,它默认没有使用,需要手动使用。
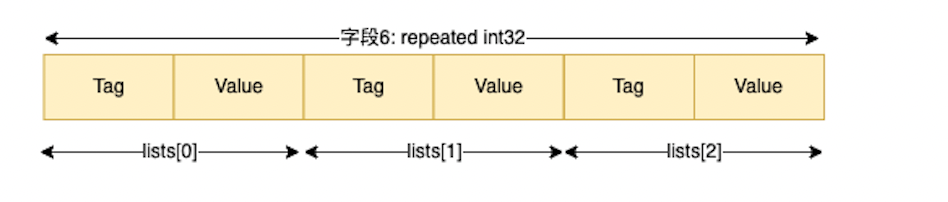
我们看没有packed的repeat,这几个Tag是完全一样的,因为它们有着一样的字符标识和Wire Type,是浪费空间的。所以才引入了packed=true的修饰。

使用Length代表Value列表的总字节长度,Value则使用Varint编码,多个Value连续储存。不需要每个Value前面放个相同的Tag,极大的节省了空间。
总结
讲解protobuf序列化,比我想象的占用了更多的篇幅,因为它的确有不少知识点要讲解,不懂这些知识点的情况下,很难深入理解这个流程。我已经尽量简化我的描述,同时能让人一眼看懂。
当然Protobuf博大精深,我们这篇博客只是针对protobuf怎么序列化的进行抽丝剥茧,理解了protobuf序列化的方式,让你使用protobuf的时候知道应该选择什么类型。有什么优缺点。
Protobuf如何保证向后兼容性的呢?
- 通过添加可选字段,不可修改已经存在的
字段标识(标签的数字)。 - 在序列化和反序列化的过程中,如果某个字段没有赋值,则不会序列化这个字段。
- 反序列化的过程中,如果发现某个字段不存在,且不是
required类型,就会忽略这个字段的反序列化,继续序列化其他字段。 - 由于proto3已经去掉了
required这个类型,所以没有这方面的担心,如果使用proto2的话,慎用required类型,尤其针对已有的结构增加新的字段。
Protobuf使用建议
基于Protobuf序列化原理分析,为了有效降低序列化后数据量的大小,可以采用以下措施:
- (1)多用
optional或repeated修饰符 若optional 或 repeated 字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要进行编码,但相应的字段在解码时会被设置为默认值。 - (2)
字段标识号尽量只使用1-15,且不要跳动使用 Tag是需要占字节空间的。如果字段标识号>15时,Tag标签的编码就会占用2个字节,如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能。 - (3)若需要使用的字段值出现负数,请使用sint32/sint64,不要使用int32/int64。 采用sint32/sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据。
- (4)对于repeated字段,尽量增加packed=true修饰
增加packed=true修饰,repeated字段会采用连续数据存储方式,即
T-L-V-V-V方式。
好了,Protobuf的序列化的知识点我们讲完了。我作为面试官来考考你:
面试官: Protobuf是怎么实现序列化和向后兼容性的?为什么它节省空间?
你 微微一笑:众所周知,小学二年级我们学过,通过Varint编码和Zigzag编码,加上protobuf定义的WireType类型,很容易的实现不同类型的二进制数据流,同时这个二进制数据流不需要像json和xml那样储存Key、标签等占用大量空间,我们通过定义好的proto结构,加上优秀的编码方式,使得我们的二进制流的每个字节的空间都是有用的,不会浪费一点空间。。。。。。
面试官: 好了,恭喜你通过面试,哪天可以入职?
<全文完>