LRU缓存机制,你想知道的这里都有
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。
概述
LRU是Least Recently Used的缩写,译为最近最少使用。它的理论基础为 “最近使用的数据会在未来一段时期内仍然被使用,已经很久没有使用的数据大概率在未来很长一段时间仍然不会被使用” 由于该思想非常契合业务场景 ,并且可以解决很多实际开发中的问题,所以我们经常通过LRU的思想来作缓存,一般也将其称为LRU缓存机制。
原理
实现LRU时,我们需要关注它的读性能和写性能,理想的LRU应该可以在O(1)的时间内读取一条数据或更新一条数据,也就是说读写的时间复杂度都是O(1)。
此时很容易想到使用哈希表,根据数据的键访问数据可以达到O(1)的速度。但是更新缓存的速度却无法达到O(1),因为需要确定哪一条数据的访问时间最早,这需要遍历所有缓存才能找到。
因此,我们需要一种既按访问时间排序,又能在常数时间内随机访问的数据结构。
这可以通过哈希表+双向链表实现:
- 哈希表保证通过key访问数据的时间为O(1).
- 双向链表则按照访问时间的顺序依次穿过每个数据。
之所以选择双向链表而不是单链表,是为了可以从中间任意结点修改链表结构,而不必从头结点开始遍历。
图解示例
假如我们设计一个容量大小为4的LRU缓存。
1.先添加4个元素
上排是哈希表的 key, 我们依次添加:k1, k2, k3, k4。
下排是哈希表的 node 结构体,里面包括(key, value) pair,我们用双向链表连接。分别为n1, n2, n3, n4。
最新添加的在链表头部,表示最近使用。
当我们添加第四个元素的时候如图所示:
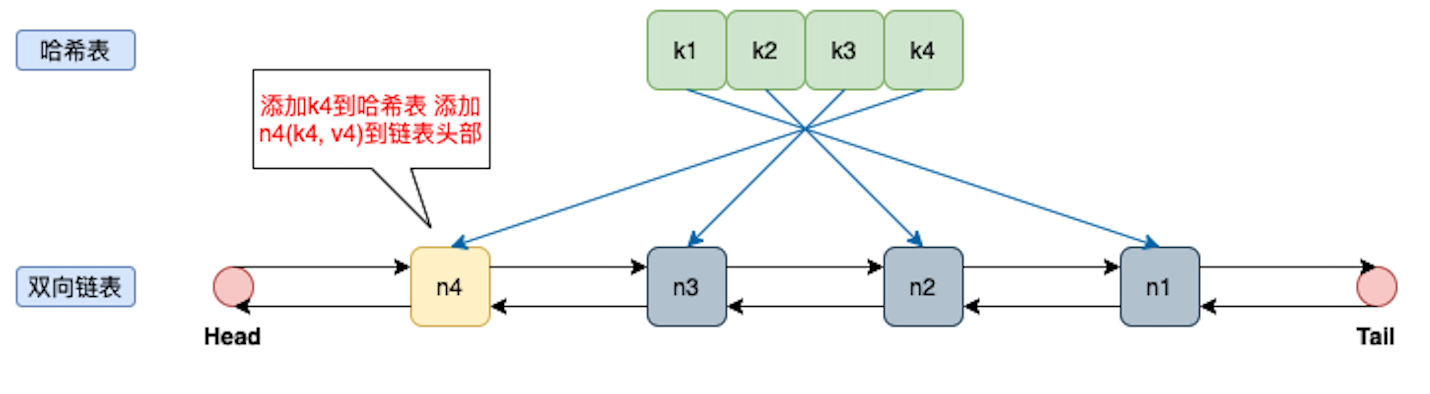
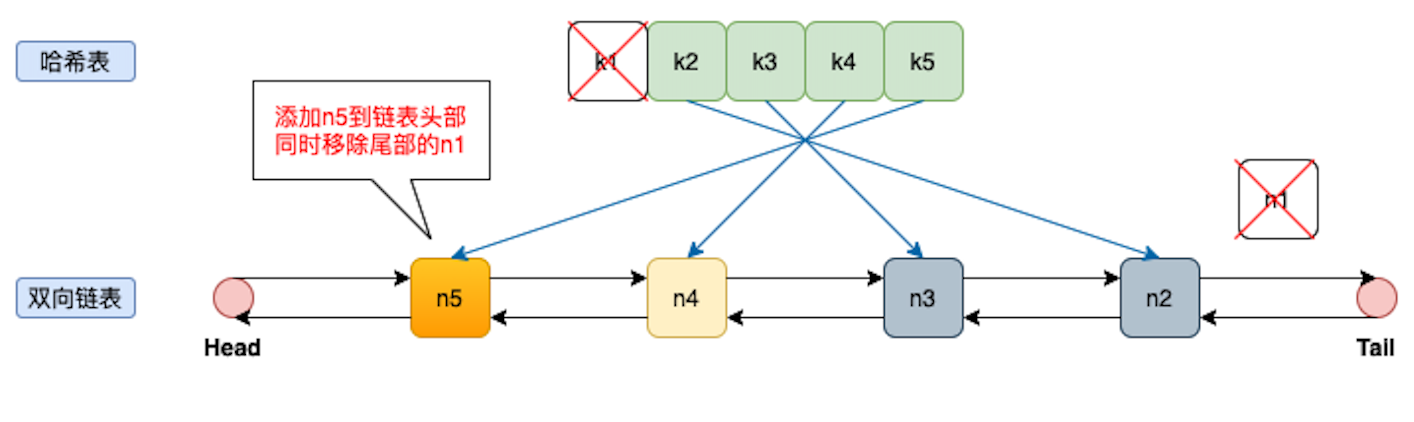
2.添加k5
把k5放在哈希表中,然后把n5放在链表头部,此时由于hash表的size大于容量4,我们需要删除一个元素,从尾部删除,尾部代表最久没使用。
同时从哈希表中删除尾部n1对应的k1。
3.访问k3
k3最近访问,把n3从当前位置删除,并插入到链表头部。
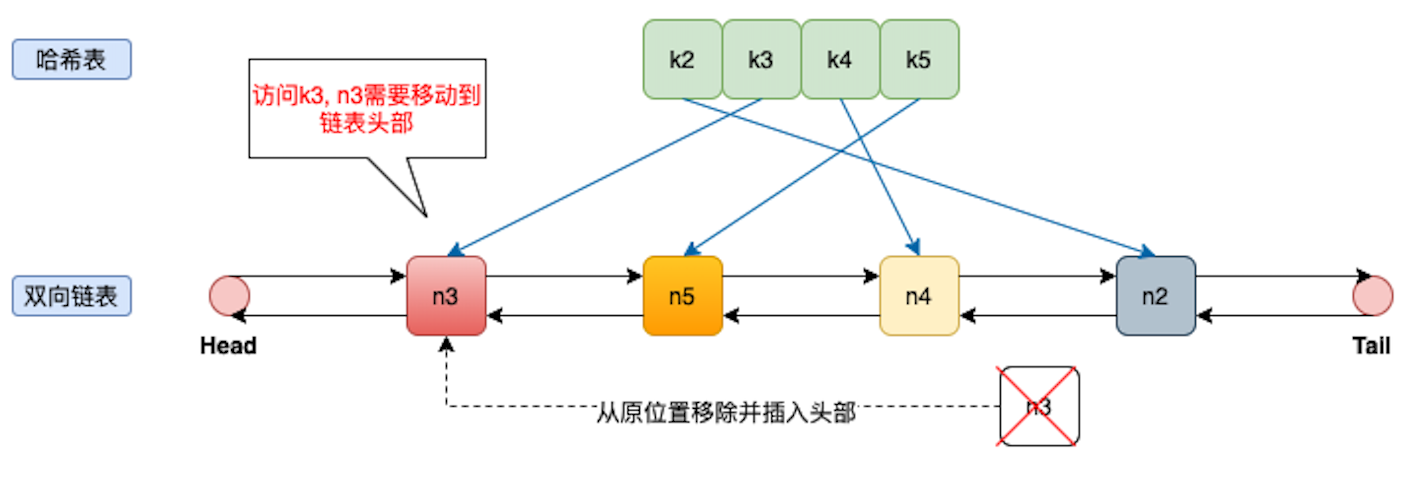
结论:
- 每次添加元素到链表中的时候都是从头部添加
- 每次删除元素的时候都是从尾部删除
- 删除的时候同时从哈希表里面删除对应的key
- 再次访问的元素,需要把元素移动到链表的头部
Leetcode
Leetcode有LRU Cache经典算法题,这道题并不难,也是我当面试官经常考的一道题。
这道题算是LRU实现的简单版本,可以当作入门练习。
https://leetcode.com/problems/lru-cache/
146. LRU 缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。 实现 LRUCache 类:
- LRUCache(int capacity) 以正整数作为容量 capacity 初始化 LRU 缓存
- int get(int key) 如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。
- void put(int key, int value) 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
C++解答:
|
|
开源项目应用
这里我会介绍LRU在各个常用的开源项目中的使用。
我会用尽量简短的语言概述,但是又能尽量包含关键信息。
Redis中使用LRU淘汰策略
Redis 作为缓存使用时,一些场景下需要考虑内存的空间消耗问题。
Redis 有很多淘汰策略,其中和LRU相关的有其中的两种:
allkeys-lru: 对所有的键都采取LRU淘汰
volatile-lru: 仅对设置了过期时间的键采取LRU淘汰
我们知道,LRU算法需要一个双向链表来记录数据的最近被访问顺序,但是出于节省内存的考虑,Redis的LRU算法并非完整的实现。
Redis并不会选择最久未被访问的键进行回收,相反它会尝试运行一个近似LRU的算法,通过对少量键进行取样,然后回收其中的最久未被访问的键。通过调整每次回收时的采样数量maxmemory-samples,可以实现调整算法的精度。
在Redis3.0中,还新增加了一个淘汰池,本质上它是一个大根堆,新随机出来的key会添加到淘汰池,然后淘汰最旧的key。
关于Redis的淘汰策略或者LRU源码分析,也可以单独出一遍博客分析,这里篇幅所限不做详细分析了。
MySQL中InnoDB引擎中缓存池LRU算法
InnoDB的缓存池:简单来说就是一块内存区域,该区域内缓存着InnoDB访问存储在磁盘的数据和索引信息。缓冲池有两个作用,一是提高了大容量读取操作的效率,二是提高了缓存管理的效率。
MySQL的InnoDB引擎从磁盘加载数据页到缓存池时,往往连带着目标数据页相邻的数据页一起加载到缓存池中–MySQL预读机制。
为什么MySQL会存在预读机制呢?
其实就是提升性能。
但是另一方面可能会发生,预读进去的数据页几乎不被访问,但是由于LRU的特性,这部分数据页在预读进去后会处于链表的头节点附近,还可能淘汰一部分本身访问比较频繁的数据页。
所以MySQL采用了基于冷热隔离的LRU策略
LRU链被拆为两部分:一部分存储热数据,一部分存储冷数据。
当数据初次加载到缓存池中时,会首先放在冷链的头部,经过 innodb_old_blocks_time (默认1s)后如果再被访问,则将缓存页移动至热链头部。
实际业务使用
实际业务中主要针对热点数据使用内存LRU缓存来降低后端数据库或者Redis缓存的压力。
电商大促
大促期间秒杀促销或者人气店铺
我们在实际业务中使用了LRU缓存,主要是为了解决热点数据的访问问题。
我们的一些数据存在MySQL中,然后使用Redis的集群作为缓存。平时由于命中率比较高,MySQL的读取的QPS相对比较低,一切都很顺利。
但是在一些大促活动期间(双11),有些热门店铺的访问量就非常高,就导致了一些热点数据,其中几个Redis节点的CPU就直接100%使用率。
于是我们针对热点数据,我们让它通过LRU缓存,来极大的缓解Redis和MySQL的压力。
怎么区分热点数据呢,有两种方式:
- 我们可以在服务端设置一些规则区分热点,请求数据满足特定的规则就认为是热点数据。
- 也可以在API请求中加入一个标记来告诉服务端这个请求的数据当作热点数据来处理,比如秒杀页面的请求就可以自动带有这个标记。
当请求到达的时候,就看是否匹配热点标记,如果是热点数据,查询LRU缓存,如果命中直接返回。 不命中就继续向Redis读取,并写入LRU,Redis如果也不命中就向MySQL读取,写入Redis。这样层层的方式,可以极大的减轻Redis和MySQL的压力。
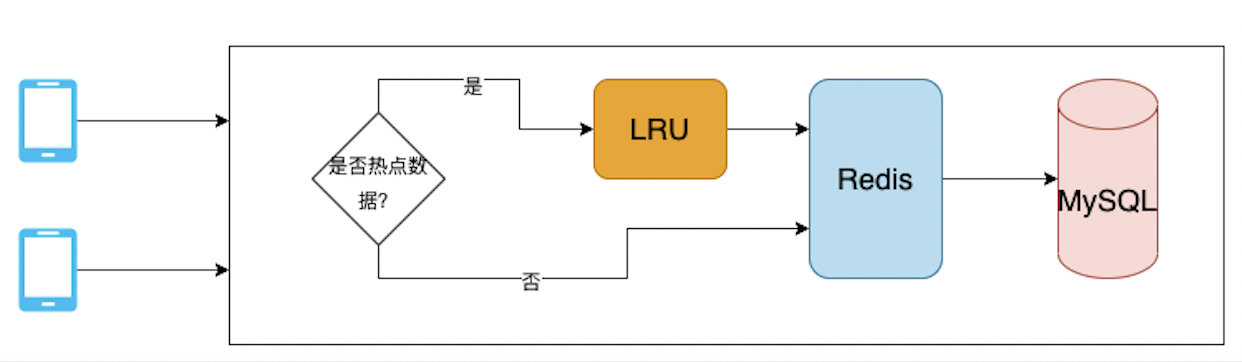
微博热搜
还有一种类似的场景就是微博热搜。
微博热搜也是一种瞬间大流量的热点数据,经常听到明星八卦导致微博直接宕机,就是热点数据没有处理好的会导致的风险。
一般可以对从热点页面进入的请求或者被服务器标记为热点的事件,都当做是热点数据,经过LRU缓存。
总结
LRU是一个在产品业务中很有用的算法,它追求空间的利用率,使用权衡的方案来把最近最少访问的数据剔除出内存。是一个很有用的算法,同时也是找工作面试中经常考察的算法之一,值得我们好好学习。
<全文完>