谈一谈热点Key解决方案
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。
背景
最近不少人问我,怎么解决热点Key问题。我说,你提到这个我可就不困了。因为刚好,我手上的两个业务都有实现热点Key解决方案并且使用了不同的方案。
我们的这两个服务都是支持百万级别QPS的服务,对热点Key的处理也算是经得起高并发的考验。
所以我就通过我们这两个服务,来谈谈热点Key的解决方案。
什么是热点Key?
就是对后端业务来说我们储存了有很多的数据量,但是单个数据的访问突然变大,导致后端的缓存/储存等无法承载,从而拖垮整个系统。
常见的一些热点事件,例如:双十一期间某些热门商品的降价促销,当这其中的某一件商品被数万次点击浏览或者购买时,会形成一个较大的需求量,这种情况下就会造成热点问题。
还比如:热卖商品、热点新闻、热点评论、明星直播,微博爆炸新闻等。像微博某个明星出了某个瓜,立刻就形成热点事件,然后微博服务直接宕机,无法访问。这就是热点数据没有处理好导致的问题。
热点Key问题的危害
- 流量集中,达到物理网卡上限。
- 请求过多,缓存分片服务被打垮。
- DB击穿,引起业务雪崩。
当某一热点Key 的请求在某一主机上超过该主机网卡上限时,由于流量的过度集中,会导致服务器中其它服务无法进行。
如果热点过于集中,热点Key 的请求过多,超过上限时,就会导致缓存分片服务被打垮现象的产生。
当缓存服务崩溃后,此时再有请求产生,会缓存到后台 DB 上,由于DB 本身性能较弱,在面临大请求时很容易发生请求穿透现象,会进一步导致雪崩现象,严重影响设备的性能。
解决方案
方案一:内存LRU缓存
这个方案可以看我的另外一篇文章:LRU缓存机制,你想知道的这里都有
电商大促
大促期间秒杀促销或者人气店铺
我们在实际业务中使用了LRU缓存,主要是为了解决热点数据的访问问题。
我们的服务储存了买家/卖家的一些属性,比如卖家的优惠券就算一种。
但是在一些大促活动期间(双11等),有些热门卖家店铺的访问量就非常高,就导致了一些热点数据,其中几个Redis节点的CPU就直接100%使用率。
于是我们针对这类的热点数据,我们让它通过LRU缓存,来极大的缓解Redis和MySQL的压力。
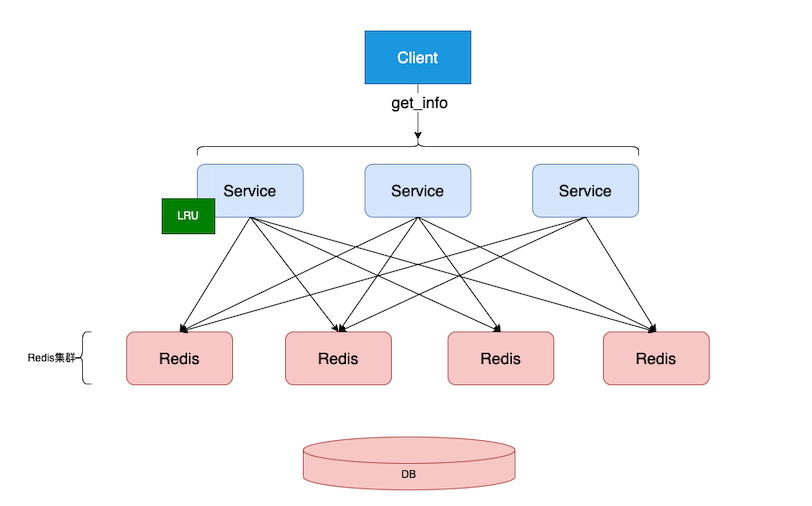
如图:
- 我们主要数据储存在DB,并缓存在Redis里面。使用Redis集群来分散储存数据。
- 当有一个热点Key落在Redis集群的某个节点上。在活动期间,用户都来访问这个key,导致某个Redis单节点CPU瞬间飙升,这个节点的访问就会极其缓慢,导致所有落到这个节点的请求都变慢。最坏情况可能会导致缓存服务崩溃,请求直接落在DB上,DB崩溃,整个服务崩溃。
在双十一的零点,我们发现Redis某一个节点瞬间CPU到达100%,然后通过log分析,是一家卖苹果商品的店铺产生了热点数据。
所以我们加了个优化。加入内存LRU缓存。把所有的卖家都经过内存LRU缓存。通过LRU的机制,过滤出最频繁使用的数据常驻内存。
难点在于怎么区分热点数据,有两种方式:
- 我们可以在服务端设置一些规则区分热点,比如我们的数据区分卖家和买家,热点数据基本都在卖家上,所以我们把卖家数据都认为是热点数据。因为我们使用了LRU,他会再次过滤真正的热点。
- 也可以在API请求中加入一个标记来告诉服务端这个请求的数据当作热点数据来处理,比如我们的促销页面,秒杀页面的请求就可以自动带有这个标记。服务端收到这个标记,就把对应的数据放入LRU中。
- 其他数据不会经过LRU。
当请求到达的时候,就看是否匹配热点标记(服务端标记+客户端标记),如果是热点数据,查询LRU缓存,如果命中直接返回。 不命中就继续向Redis读取,并写入LRU,Redis如果也不命中就向MySQL读取,写入Redis。这样层层的方式,可以极大的减轻Redis和MySQL的压力。
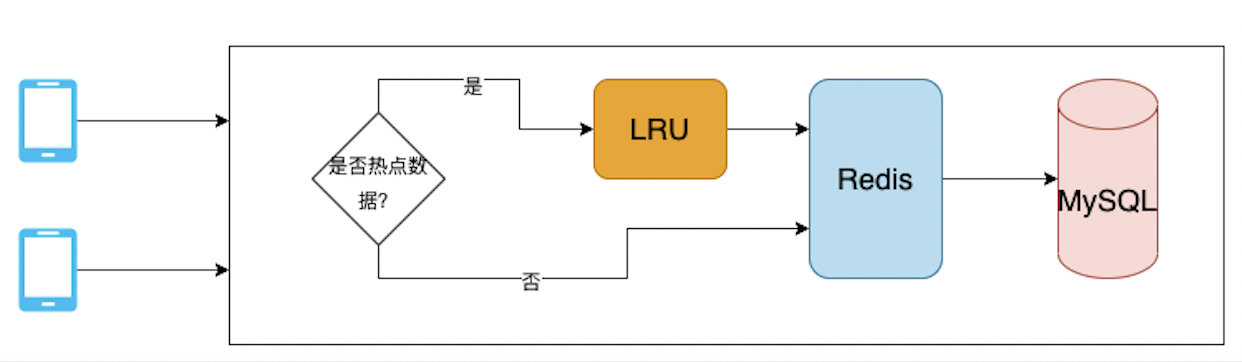
我们优化之后,Redis非常稳定,再也没出现过单节点CPU过高的情况。
微博热搜
还有一种类似的场景就是微博热搜。
微博热搜也是一种瞬间大流量的热点数据,经常听到明星的大事件导致微博服务直接宕机,就是热点数据没有处理好的会导致的风险。
一般可以对从热点页面进入的请求或者被服务器标记为热点的事件,都当做是热点数据,经过LRU缓存。
当然了,具体的案例具体问题,热点储存本身不难,主要是你怎么预先识别哪些数据是热点数据。
方案二:热点数据分片
我们还有一个服务使用了不一样的做法,使用了热点数据分片。
比如我们有一个分布式的服务,使用了Redis集群作为后端储存/缓存。同时我们有一个admin复制设置哪些实体是热点数据。
这个场景的热点数据是固定的,比如给某个商家配置了一个促销活动。在促销活动期间,这个商家就是热点的商家。这种热点非常明确。
比如正常的key是user_info_123456,那么对于热点数据,我们就给他分片:user_info_123456_01~user_info_123456_20
不同的Key就通过路由规则分散储存在不同的Redis节点上。
我们的Redis节点储存了三类数据。
Key: user_info_{id} // 1. 非热点数据
Key: user_info_{id}_[1,20] // 2. 热点数据,会分散在不同的Redis节点上。
Key: hot_key_list // 3. 具体的热点key的列表,分布式服务器会定时拉取这个列表,以便服务器知道哪些Key是热点数据,可以做不同的访问处理。
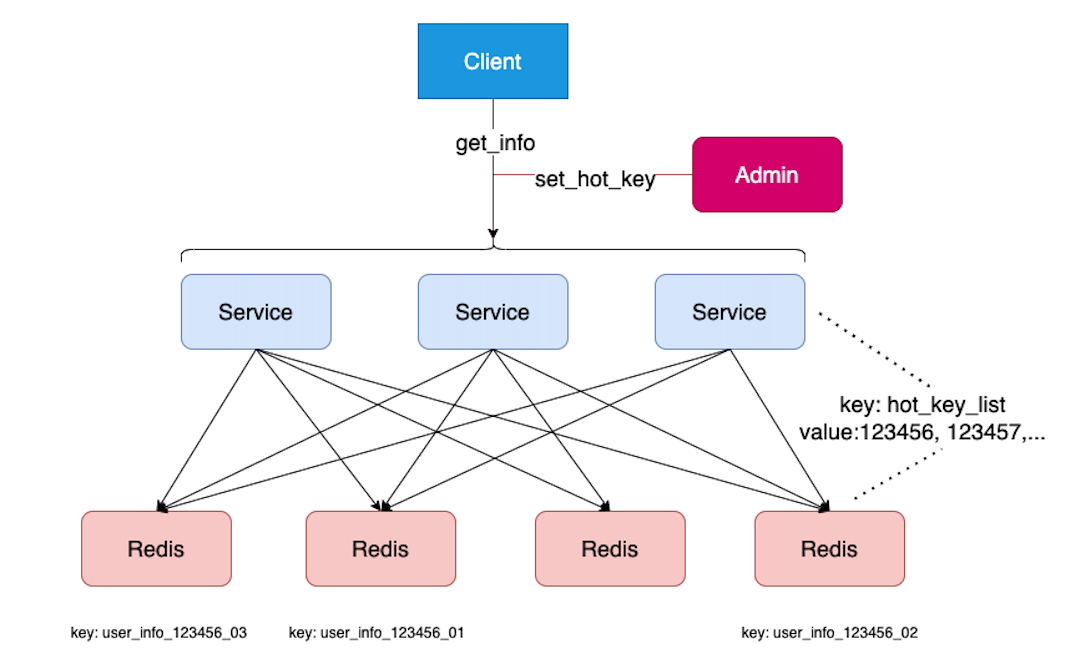
一、关于热点Key列表同步。
问题一:set_hot_key可能访问任何一台Service,分布式的其他Service怎么知道哪些是hot_key呢?
数据是储存在Redis里面的,然后每台服务器会定时拉取Redis的数据来保持同步。
Redis:
key: hot_key_list
value: "id1:expire_time,id2:expire_time,id3: expire_time,..."
Service:
hot_key_list = {id1: expire_time, id2: expire_time, id3: expire_time, ...}
- 我们的设置热点数据
API:set_hot_key在Service负责从Redis取出热点数据,把新的热点数据放进去并过滤掉过期的数据,然后再写入Redishot_key_list。 - 同时从Redis里面取出具体的数据
user_info_{id},复制多份并对Key使用不同的后缀user_info_{id}_01~user_info_{id}_20,重新写入Redis,此时热点数据就分散储存在不同的节点上了。 - 同时我们每一台Service会有一个定时器去Redis读取最新的热点数据的列表
hot_key_list,保存在本服务器内存中。这样就保证了每台Serivce都知道哪些key是热点数据的Key了。
问题二:客户端访问数据的时候是怎么处理的?
- 如果非热点数据,直接就访问Key:
user_info_{id} - 如果在内存中查到是热点数据,就对后缀做随机 Key:
user_info_{id}_{1~20}, 这样就可以保证每次对热点数据都是随机访问任意一个Key。大大的降低了热点的可能。
这就需要客户端/管理者知道哪些是热点数据,可以是提前后台配置的,也可以是某个活动事件触发的。我们标记上热点数据和过期时间。就可以在特定的时间把数据当作热点数据储存。防止热点数据导致的单点故障。
总结
在高并发场景下,热点数据是一个很常见的问题,热点数据的解决方案有多种,难点还是要怎么识别哪些数据是热点数据,这样我们才能在热点出现的瞬间,服务器能稳定的处理热点事件。
而热点数据的难点就是怎么识别哪些数据是热点数据,这种要具体案例具体分析。我们的案例就相对简单,卖家数据是热点,促销界面是热点,秒杀界面是热点,活动界面是热点 等等。
所以当你遇到热点数据的时候,也要找到一个合适的方式去识别和储存,才能让我们的服务器稳定的服务。
<全文完>