点赞和评论 技术设计与实现
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。
上篇文章介绍了朋友圈的技术设计,这篇将介绍朋友圈点赞和评论的实现方式。
需求介绍
- 对某条状态实现点赞与取消点赞的功能。
- 点赞列表按时间从小到大排序。
- 点赞列表支持分页查询。
- 对某条状态实现评论和删除评论的功能。
- 评论列表按时间从小到大排序。
- 评论列表支持分页查询。
技术分析
原始方案
由于评论和点赞的数据量可能非常大,所以一开始用了缓存来降低DB的查询频率。 Cache更新策略采用了监听MySQL的Binlog来更新Cache的方式,而不是应用层在写DB的时候同步写Cache的方式。 因为这样可以把DB写入和Cache写入解耦,应用层只用关注DB的写入,把Cache当作DB的一个Slave一样同步更新。
由于点赞和评论系统基本一致,评论会稍微略复杂,因为多了一个评论内容。这里就以评论系统为例,看一下整个系统如何设计。
定义结构
首先看一下数据储存格式:
|
|
并定义了protobuf映射comment_tab的一行数据。
|
|
需求分析
- 获取评论列表,支持分页。
Request:
activity_id,
cursor, //cursor默认为0,下次请求的cursor为上次返回的cursor以便可以分页向后查找。
limit, //每次查询的次数。
Response:
Array of CommentData
cursor
- 增加评论。
- 删除评论。
设计图如下:
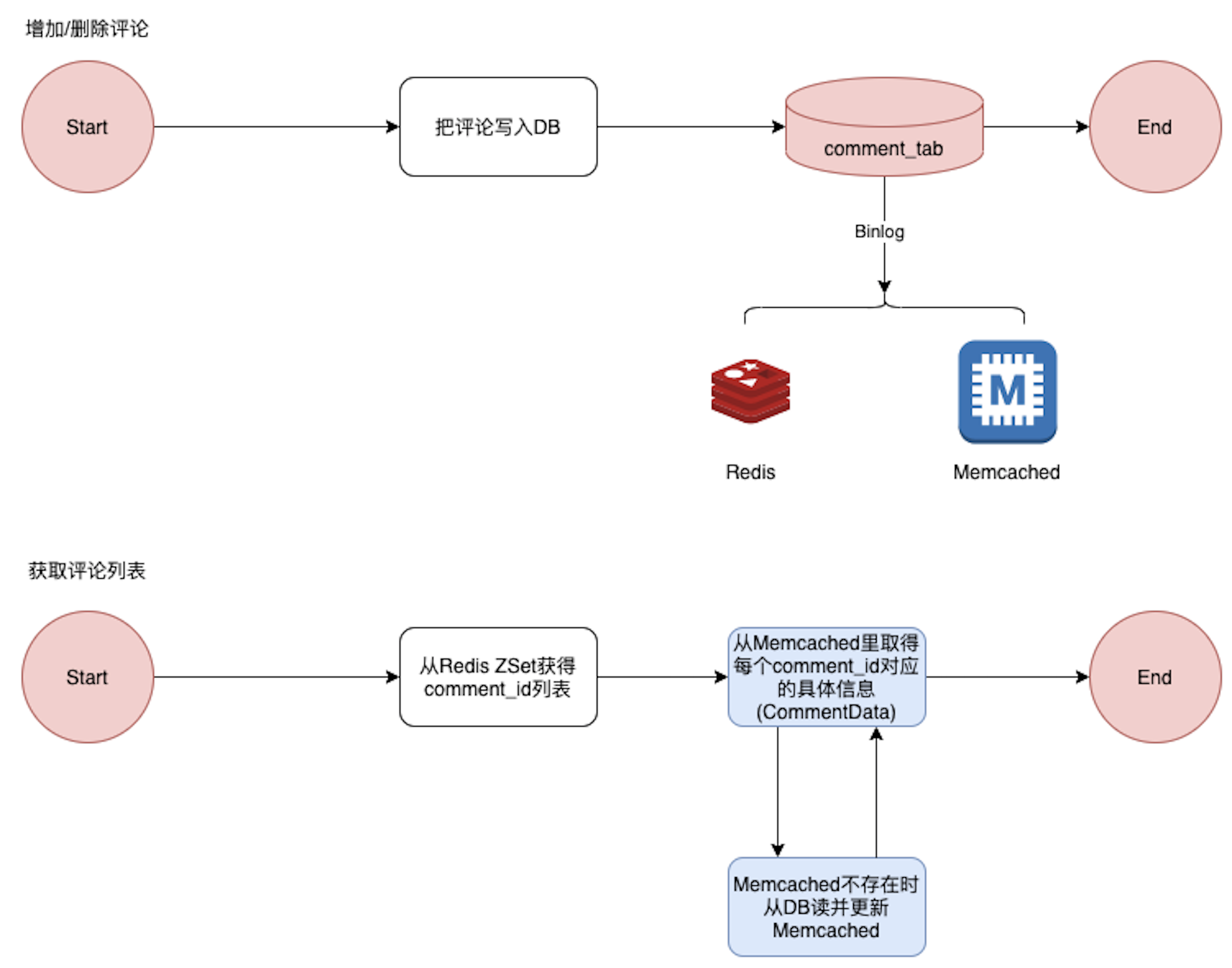
解释一下上图的缓存设计,这里设计了两层Cache。
Memcached
Key: comment_id
Value: Marshal(CommentData)
代表的是某一条Comment数据的序列化。
Redis ZSet
Key: activity_id
-- member: comment_id
-- score: update_time
代表的是某一条activity_id所有的comment,按score(update_time)排序。可以很方便的支持分页。
我们的DB使用了TiDB,兼容绝大部分MySQL语法,是分布式的数据库,数据量大的时候使用TiDB更加高校,可以支持方便扩容。 但是跟DBA讨论之后,DBA不赞同这种实现方式,他们认为社交场景下流量峰值是不可控的,比如微博热门事件经常会导致服务不可用。
- 直接同步写DB会导致DB压力会非常大,他们建议我们使用内存数据库作为真实数据源,并且异步备份存到TiDB上,这样DB的写入QPS可控。所有读的流量只经过内存数据库(Redis)而不经过TiDB。
- TiDB的Binlog不稳定,不建议使用。(原因? TiDB binglog )。
进阶方案
此方案下我们使用Redis的持久化模式作为数据源,然后异步备份到TiDB。
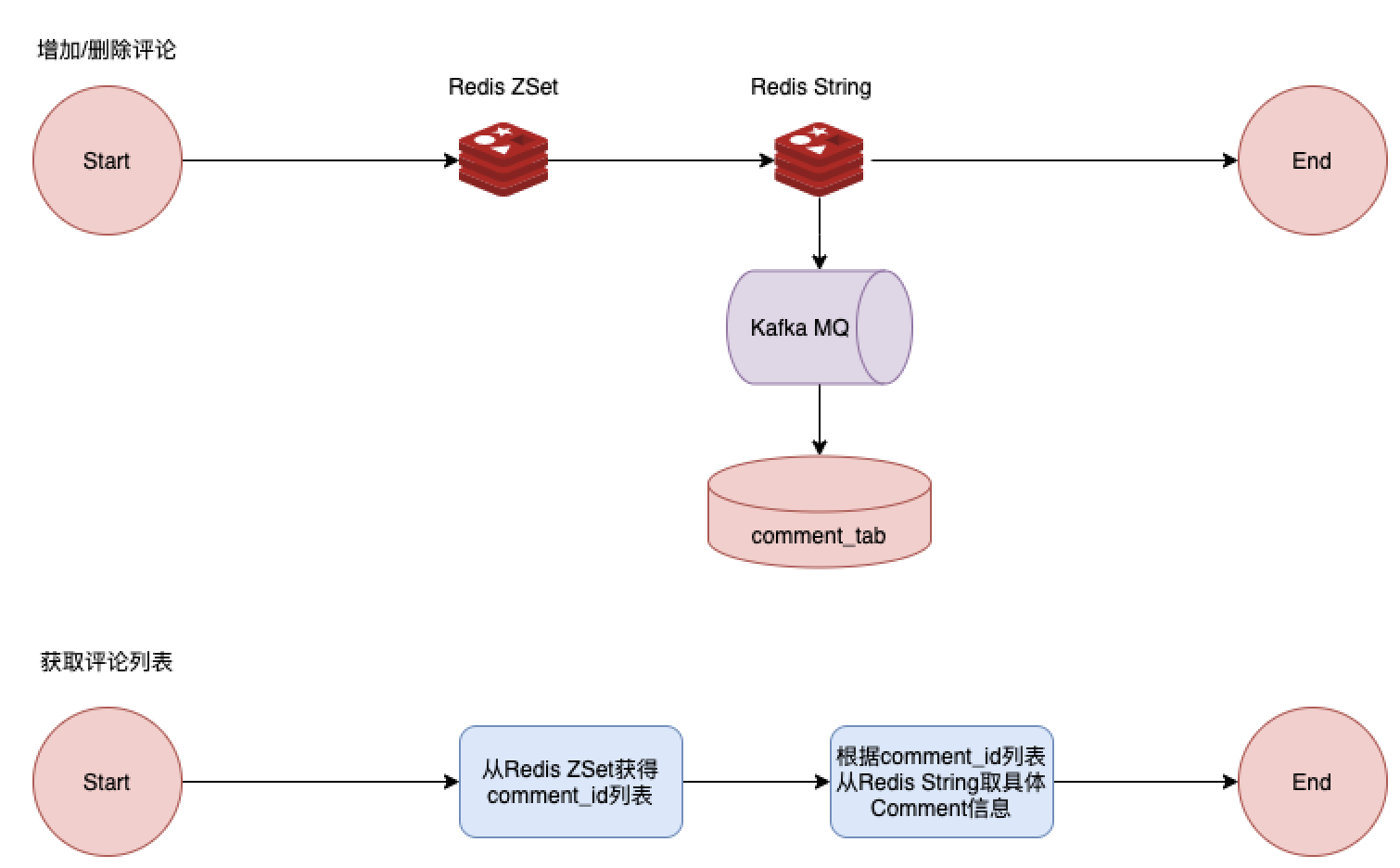
此方案使用了异步写入DB的方式,可以流量消峰,应用层使用Redis来服务用户,并使用Redis的String类型代替Memcached(因为Memcached不支持持久化), Redis作为内存数据库,查询速度非常快。 只是在数据量非常大的情况下,需要申请非常多的内存资源。
在这里我们需要两种类型的数据来储存评论的数据。
Redis String
Key: comment_id; Value: proto.Marshal(CommentData)
Redis ZSet
Key: activity_id; – member: userid; – score: update_time;
比如每次查询limit=100, 那我想要查询下100个怎么办呢,需要把上次返回的最后一个的score作为cursor返回,这样下次查询带着这个cursor查找。 因为ZRevRangeByScore以及其他类似的Cmd都是支持Max,Min,Limit等查询参数的。 在这里,Max: “(curosr”, Limit: “100”.
问题总结
到这里已经有一个相对完整的技术方案了,但是这个方案还有一些问题。
- 使用update_time作为score, 由于update_time是second级别,有很大的概率重复(多个用户同时评论同一个activity_id). 这会导致分页查询的时候会导致数据数据重复或者遗漏。(因为我们比较的时候是用大小比较的)。 这有人就问了,为什么不直接用Offset和Limit呢,这样每次直接从指定位置查询。不用管score的大小,重复也没关系。 这种方案会有两种问题:
- 如果你分页向下查找的过程中,有了一条新的评论。比如你第一次取了1-100,第二次取101-200,在你第一二次之间有一个新的评论进来,由于它是最新的,会变成1号评论,所有其他的评论都会下降1位,导致你第二次取101-200中的101是上次的100. 导致重复。使用cursor使用score比较的,不会出现这个问题。
- 拉取列表的时候,有可能有一些过滤条件,比如,只有你的好友的评论才能展示,那有些评论可能就需要过滤掉。你只显示了100条,但是实际上可能在Redis里面查询了351条。下次需要从352条开始查。你怎么把offset=101根352映射起来呢。
所以我们才用了cursor的方式,无论是查询DB还是查询Redis都是一种比Offset更好的解决方案。可能他的缺点就是规则要固定,不能这次我用update_time排序,下次我用userid排序这种情况。
使用cursor怎么解决这种情况呢,有人可能会说,可以把timestamp改为int64的nanosecond啊,这种方案跟我们下面的方案有着同样的问题。
我根据snowflake算法把update_time变成一个int64的唯一的随update_time递增的ID。
snowflake算法介绍如下:
snowflake
心想,这样终于能解决问题了吧,cursor变成了唯一的值,每次使用上次返回的最后一个cursor来查询下次的分页数据,应该不会重复了吧。
然后问题又出现了,依然出现了重复。
查看Redis ZSet数据如图:
 最后在Redis的官方文档上发现了以下的话。
最后在Redis的官方文档上发现了以下的话。
Range of integer scores that can be expressed precisely
Redis sorted sets use a double 64-bit floating point number to represent the score. In all the architectures we support, this is represented as an IEEE 754 floating point number, that is able to represent precisely integer numbers between -(2^53) and +(2^53) included. In more practical terms, all the integers between -9007199254740992 and 9007199254740992 are perfectly representable. Larger integers, or fractions, are internally represented in exponential form, so it is possible that you get only an approximation of the decimal number, or of the very big integer, that you set as score
是的,score采用了 double 64-bit floating point number. 支持的int最大值是(2^53-1) 所以我改造了以下snowflake算法。 Redis ZSET问题分析及解决方案
- 另外,由于前端调用我们的借口使用了json的序列化方式。 可以看到JavaScript同样使用了IEEE 754,也就是说也只是支持到(2^53-1)的最大值。
Javascript Number.MAX_SAFE_INTEGER 所以大于(2^53-1)的数是不能正常的序列化和反序列化的。
数据一致性
我们先保证了Redis数据更新成功,然后使用MQ异步写入TiDB,怎么保证Redis数据和TiDB的数据的一致性呢。 进阶方案好像并没有使用TiDB,那把数据写入TiDB有什么用呢。
- 以防Redis故障可以从TiDB导入数据。
- TiDB数据方便做数据分析和统计。
<全文完>