后端面试必备 - MySQL更新优化的几个阶段
本篇博客的视频教程首发于 Youtube:科技小飞哥,加入 电报粉丝群 获得最新视频更新和问题解答。
背景
现在的互联网大厂,都经历了数据量和访问量从零到亿级别的飞速增长。在这业务增长的过程中,也会面临很多技术的重构与优化,来支撑业务的快速扩张。
这篇文章,我就通过我们团队的经历,讲一下我们在业务量飞速增长的过程中,我们数据的更新优化的几个阶段。也许很多更新优化你都听说过,这里记录我们完整的优化过程,以及我们的思考。
前面几个阶段比较常见,最后一个优化的阶段是我们做的一个大胆的尝试,最终事实证明了,我们最后的优化帮我们节省了80%的DB资源,也帮我们安全度过了一个个大促活动。
零、初始版本
这是初始版本,假设你们公司要做一个电商网站,需要支持账号注册/登录。
那我们最先考虑的就是有一张用户表储存用户相关的基本信息,我们叫它user_tab。
| 字段 | 备注 |
|---|---|
| userid | 主键,唯一id |
| phone | 手机号 |
| 邮箱 | |
| passowrd | 密码 |
| register_time | 注册时间 |
| login_time | 最近登录时间 |
| logout_time | 最近登出时间 |
| …… | 其他一些字段 |
有了这个用户表,那我们网站的用户注册登录的基础信息就可以保存了。在网站的初始阶段,由于用户和访问量都不多,一切都很平稳。
一、加缓存
然后由于业务发展比较好,用户量和访问量达到了一定的规模,那么用户查询数据库就成了性能瓶颈。这个时候通常的做法就是加缓存。
我们给这个user_tab加个memcached/Redis的缓存。
一般缓存能保证最终一致性,却很难保证强一致性。在绝大多数业务来说,也只需要保证最终一致性就可以。
一般来说,缓存最终一致性有两种方案。
1. Cache Aside Pattern
Cache Aside Pattern 意为旁路缓存模式,是应用最为广泛的一种缓存策略。
- 在读请求中,首先请求缓存,若
缓存命中,则直接返回缓存中的数据; - 若
缓存未命中,则查询数据库并将查询结果更新至缓存,然后返回查询出的数据。 - 在写请求中,先
更新数据库,再删除缓存。
这里最让人感觉疑惑的是,为什么要删除缓存,而不是更新缓存?
更新数据库后删除缓存是用来保证最终一致性的。如果是更新缓存,数据库写和缓存写并非原子性,可能会导致以下问题:
- 并发写入同一份数据时,缓存写入顺序不一致,导致脏数据。
- 写入失败导致脏数据。
而更新数据库后删除缓存,则保证了有任何改动都去删除缓存,下次读的时候从DB同步到缓存,就能保证最终一致性。
基于数据库日志MySQL binlog的增量解析、订阅和消费
这是很多企业使用的方案,为的是减少业务层对缓存操作导致的业务复杂性和易错性。
一个相对成熟的方案是通过异步订阅MySQL binlog的消息,对增量日志进行解析和消费。
这里较为流行的是阿里巴巴开源的作为MySQL binlog增量获取和解析的组件canal。
canal sever模拟MySQL slave的交互协议,伪装为MySQL slave,向MySQL master发送dump协议。MySQL master收到dump请求,开始推送binary log给slave(即canal sever)。canal sever解析binary log对象(原始为 byte 流),可由canal client拉取进行消费,同时canal server也默认支持将变更记录投递到 MQ 系统中,主动推送给其他系统进行消费。- 在 ack 机制的加持下,不管是推送还是拉取,都可以有效的保证数据按照预期被消费。
由于我们使用的是go语言,使用了go语言版本的MySQL binlog订阅,github go-mysql,后续我会做一篇源码分析来分析MySQL binlog相关的方方面面。
二、垂直拆分
缓存方案实际上适用于读多写少的用户场景,因为每次数据更新都会导致缓存失效。但是我们的用户表的设计,因为用户每次登入登出,都需要修改一些易变的字段,login_time和logout_time, 每次修改都需要删除缓存,就会降低缓存的命中率。导致流量集中在DB上,影响我们业务整体的性能。
这个时候怎么办呢?我们第一步就是做垂直拆分。
垂直拆分是把易变的字段从表中拆分出来,形成一个单独的表。这样就有了两个表。
- 一个是
user_tab, 用户主要信息表,主要流量是读,我们方便加缓存。如果大量的写会导致缓存的删除,发挥不了缓存的优势还会经常的访问数据库。 - 一个是
user_ext_tab, 用户信息中易变的信息表,主要流量是写,我们可以拆分出来,如果写入出现瓶颈,可以使用后续途径优化。
这样由于user_tab已经没有易变的数据,缓存能长时间保持有效,大大提高缓存的命中率,降低DB的访问QPS。提升我们整体的性能。
另一张表,user_ext_tab,是一个经常需要更新的表,单独拆分出来,如果有性能问题,我们也方便单独优化。
三、水平拆分
当一张table的数据量过大,比如千万级及以上,会导致B+数的层级过高,而我们推荐的InnoDB的B+数层级是不超过3级,过高的层级会导致数据库操作时过多的磁盘IO,会影响数据库的读写性能。这个时候我们需要考虑水平拆分(分表)。
关于一颗B+树可以存放多少行数据,可以查看我之前的博客。后端面试之MySQL-InnoDB一颗B+树可以存放多少行数据?
常见的拆成10~1000个表,我们这里假设拆分成1000张表。
user_ext_tab_00000000~user_ext_tab_00000999, 我们通过userid%1000对userid取模来决定某个userid对应的数据应该读写哪张表。
这样每个表的数据量就大大降低,保持我们的每个表的数据量维持在一个比较低的水平,保证了InnoDB的B+树的层级,降低了磁盘IO,提高了数据库的访问性能。
四、消息队列
拆分之后性能开始平稳了,一切看起来都很美好,然后公司要搞一个双十一活动。在双十一零点的时候,流量瞬间增加几十倍,导致数据库的压力瞬间增大,几乎承载不住。虽然这个流量是瞬间的,一会就恢复正常,但是这个峰值是一个风险,可能导致数据库宕机,影响所有的线上业务,这是一个很大的风险。
这个时候就需要用到消息队列,消息队列的特性解耦,异步,削峰刚好满足我们当前的场景。
每当需要更新user_ext_tab的时候,我们把更新的事件发送到消息队列中,消息队列里面的消费者通过消费消息来更新数据库,我们可以加一个速率控制,避免数据库的更新QPS过高导致数据库性能问题。这样即使遇到流量抖动,我们的数据库也能平稳的更新数据。
问题完美解决,可能这个时候你觉得可以睡个好觉了,再也不用担心性能问题了。
五、分库
业务发展太快,除了用户量提升之后,整体流量也提升了。流量提升就会导致访问数据库的QPS提升,这个时候数据库实例的网络IO,CPU,磁盘IO都会跟着提升。即使我们做了水平拆分,但是我们单台机器能承载的流量是有上限的。所以我们下一步我们需要做分库。
由于我们之前已经做过分表,所以分库比较方便,直接把单一数据库分成10个数据库,部署在10台机器上。每个数据库就有100个表。
六、批量更新 - 终极杀招
以上的步骤都是比较常见的步骤,而这么不停的拆分和扩容也不是办法,毕竟机器都是钱。我们需要想办法优化来缩减资源并提升性能。
所以我们想出了这么一个终极大杀器,批量更新,它帮我们度过了一个又一个的大促活动。所以我就主要讲讲我们这一步怎么优化的。
我们的更新QPS一直在增长,即使分库分表之后,每个库的update QPS也非常高,导致数据库的CPU,磁盘IO,网络IO非常高。
最后我们使用批量更新的方式,把数据先更新到缓存,然后批量取固定量的数据一起更新DB。
批量更新说起来简单,但是操作起来却有很多细节,这里我们来讲讲我们设计和实现的那些细节。
我们的批量更新分为几个步骤:
- 数据写入Cache并记录在ZSET里面
- 任务调度,从ZSET批量取出需要更新的数据,并发读取缓存,执行批量更新。
- 自动调度,增加或减少调度器时能自动调整任务分片,保证数据不重复,不丢失。
下面来详细讲讲具体的流程。
写入Cache
我们要批量更新的第一步就是写入cache,我们使用Redis的Hash来储存Cache。当然你想用String自己做序列化和反序列化也是可以的。
Key: {prefix}_userid
Value: `login_time`: timestamp
`logout_time`: timestamp
`...`: ...
有了Cache之后,我们想要批量更新,还需要一个把我们需要更新的列表列出来。
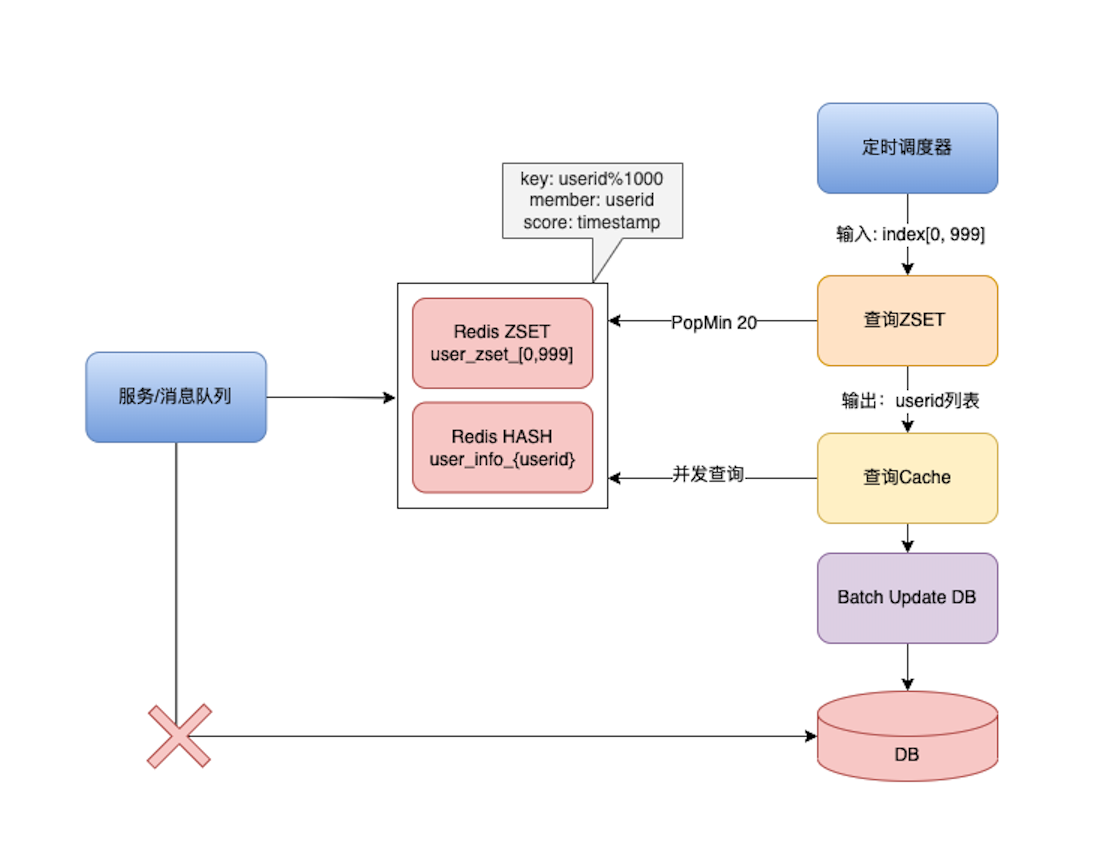
这里我使用了 Redis的ZSET来储存需要批量更新的数据。由于上面我们已经分了1000个表,所以我们需要1000个ZSET,每个ZSET负责单一的表。
Key: {prefix}_[0,999]
Member: userid
score: timestamp
这样,每次我们需要把数据写入Cache的时候,把userid插入ZSET中,这样我们就知道哪些userid的数据需要批量写入DB中。我们的调度器就能通过ZSET知道哪些userid的数据需要更新,再通过Cache找到需要更新的具体数据,进行批量更新。
批量更新语法
批量更新的语法就是UPDATE SET CASE WHEN的语法。
UPDATE user_ext_tab_00000000
SET login_time = (
CASE
WHEN userid = 11000 AND login_time < 1234567890 THEN 1234567890
WHEN userid = 12000 AND login_time < 1234567890 THEN 1234567890
WHEN userid = 13000 AND login_time < 1234567890 THEN 1234567890
ELSE login_time
END
),
login_out = (
CASE
WHEN userid = 11000 AND logout_time < 1234567890 THEN 1234567890
WHEN userid = 12000 AND logout_time < 1234567890 THEN 1234567890
WHEN userid = 13000 AND logout_time < 1234567890 THEN 1234567890
ELSE logout_time
END
)
WHEN userid IN (11000, 12000, 13000);
这里需要注意:
- 批量更新的数据量不能太大,如果更新1000条,占用的锁资源更大,如果刚好有其他SQL在访问这些行,就锁等待了。所以一般建议100行以内,我们选择的是20。
- 批量更新的IN里面最好为主键,且有序,因为MySQL的物理行储存是按主键的顺序,这相当于顺序IO,一次更新一片区域。
- 批量更新设计的好可以极大减少CPU/网络IO/磁盘IO的使用率。
批量更新流程
批量更新我们需要一个定时调度器(scheduler)来定时扫描ZSET,我们生产环境设置的是20ms,如果流量更大的情况下,我们可以调节这个值来控制更新的速率。
我们定义1000个表是1000个任务分片。
- 不写入DB,而写入Cache,并把userid记录在ZSET里面,以便后续的批量更新。
- 启动一个定时调度器,对1000个任务分片进行循环POP ZSET。取出userid的列表,执行批量更新。
自动调度
我们现在能执行批量更新了,但是调度器是单实例的。如果调度器宕机或者无法支撑这么高的数据量,依旧会出问题。
所以我们需要能自动调度,可以部署多台,且每台只负责一部分的任务分片。同时任务分片不重复,不遗漏。由于定时器是彼此独立的,如果没有中央服务器来进行调度的话,我们很难保证增加或者减少调度器的时候能自动调整自己负责的区域。
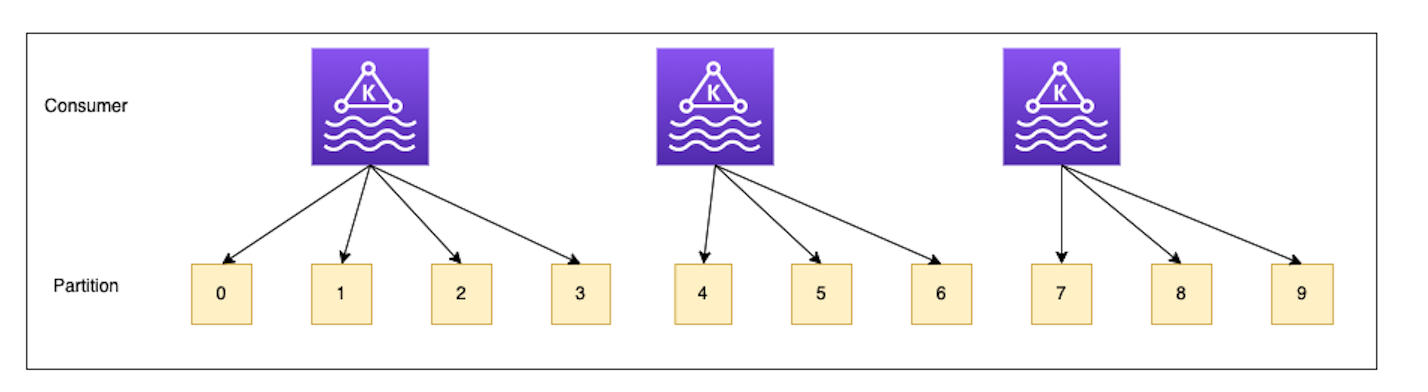
这里我们使用了Kafka的Partition机制来进行调度。
众所周知,小学二年级我们学过,当Kafka的同一个group消费同一个topic消息的时候,每个consumer会负责1到多个partition,我们增加或者减少consumer的时候,会自动调整消费的partiton。所以我们的consumer的数量要小于等于partition的数量,否则有些consumer会无法消费消息。
这里我们有10个partition,三个consumer,如果增加或者减少一个consumer,partition会自动重新分配,保证consumer和partition一对多的映射关系。
我们利用Consumer负责的partition自动调整的机制,来实现我们的调度器。
假设,我们申请一个有10个partition的Kafka topic。我们初始化定时调度器的时候注册多个Consumer。
那么,这几个Consumer就负责10个partition。我们设计一个映射算法,10个partition映射到1000个任务分片上面。这个算法是固定的,也就是Partition和任务分片一定是一对多的对应关系。
我们每次调整调度器数量的时候,比如增加一个调度器,就会额外注册一个Consumer,Partition就会重新分配,依然保证了consumer和partition一对多的映射关系。这样就自动调整了调度器负责的任务分片的数量。
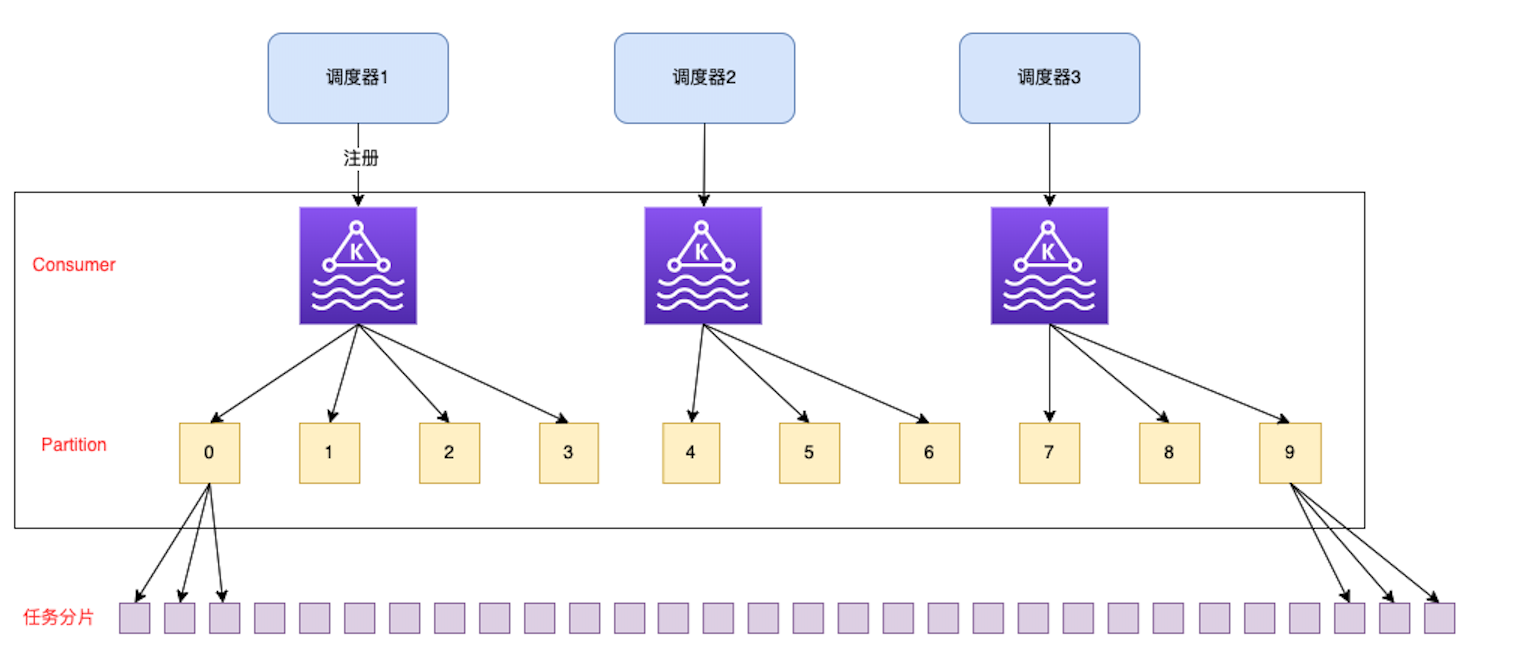
而每一个任务分片就执行上述批量更新的流程,即使某一个调度器宕机了,partition会自动分配到其他在线的Consumer上,导致其他的Consumer自动分配所有的Partition。最终依然会保证我们的调度器能够处理所有的任务分片。
用了这个批量更新的方式,我们的MySQL的CPU,磁盘IO,网络IO都降低了80%以上。这也是我们更新的终极方案了。
结论
也许你会问,为啥不一步到位直接进行最后一步呢。
引用一句话,过早优化是万恶之源。你永远不知道你的业务最终能到达什么程度,优化是在业务增长的过程中,一步一步进行的。
只要我们保持良好的代码风格,就可以进行很方便的优化。但是不要过度优化。
<全文完>